
Training a new AI voice for Piper TTS with only 4 words
Over the last 15 years (!) I have used Text-to-Speech (TTS) systems for various projects including a fairly elaborate home automation system,1 a distributed public announcement system and a monitoring system.2
I’ve wanted a specific voice for my projects for some time, as well as some kind of excuse to get me interested in AI theory and local AI experiments.
Recently I had an idea to train my favourite TTS engine, Piper TTS with a single phrase from a demo of a commercial TTS engine. Here’s how I did it, with all the details and code do you can do it too!
The difference between this method and more traditional AI voice cloning is that the hardware required for inference is minuscule – you could run the result on a Raspberry Pi!
Why might you want to do this specifically? Perhaps you’d like a custom voice for Home Assistant with little manual effort – home assistant can use Piper TTS voices directly.
You could clone a TTS engine like me, your own voice, or a character from a game or whatever else you like. The process is the same.
Background
State of the art
Espeak, Festival and Picotts
Generally, up until about 2020 the voice synthesis engines available to the hobbyist lagged behind the commercial offerings. We had the likes of espeak-ng – a technically capable, but somewhat synthetic sounding engine, picotts3 and festival which both sound better than espeak, but not fantastic especially when compared to the commercial festival offerings.

Used as the default TTS engine on Android for a long time. There’s also a fork with improvements called nanotts. ↩︎
Piper and AI based TTS
In 2023, along came Piper TTS which really broke the mold. Piper is AI based, but critically is incredibly fast and has low requirements so it can run on weak hardware – or strong hardware with low overhead. The voices it produces are quite realistic – not perfect but certainly far better than the engines of yore. Piper is part of the Open Home Foundation and widely used, so its future seems secure.

Alongside piper there have been a number of other AI based TTS engines – some of them are incredibly realistic to the point where it’s not really possible to tell the result isn’t a human voice. For instance, CosyVoice and Chatterbox TTS.

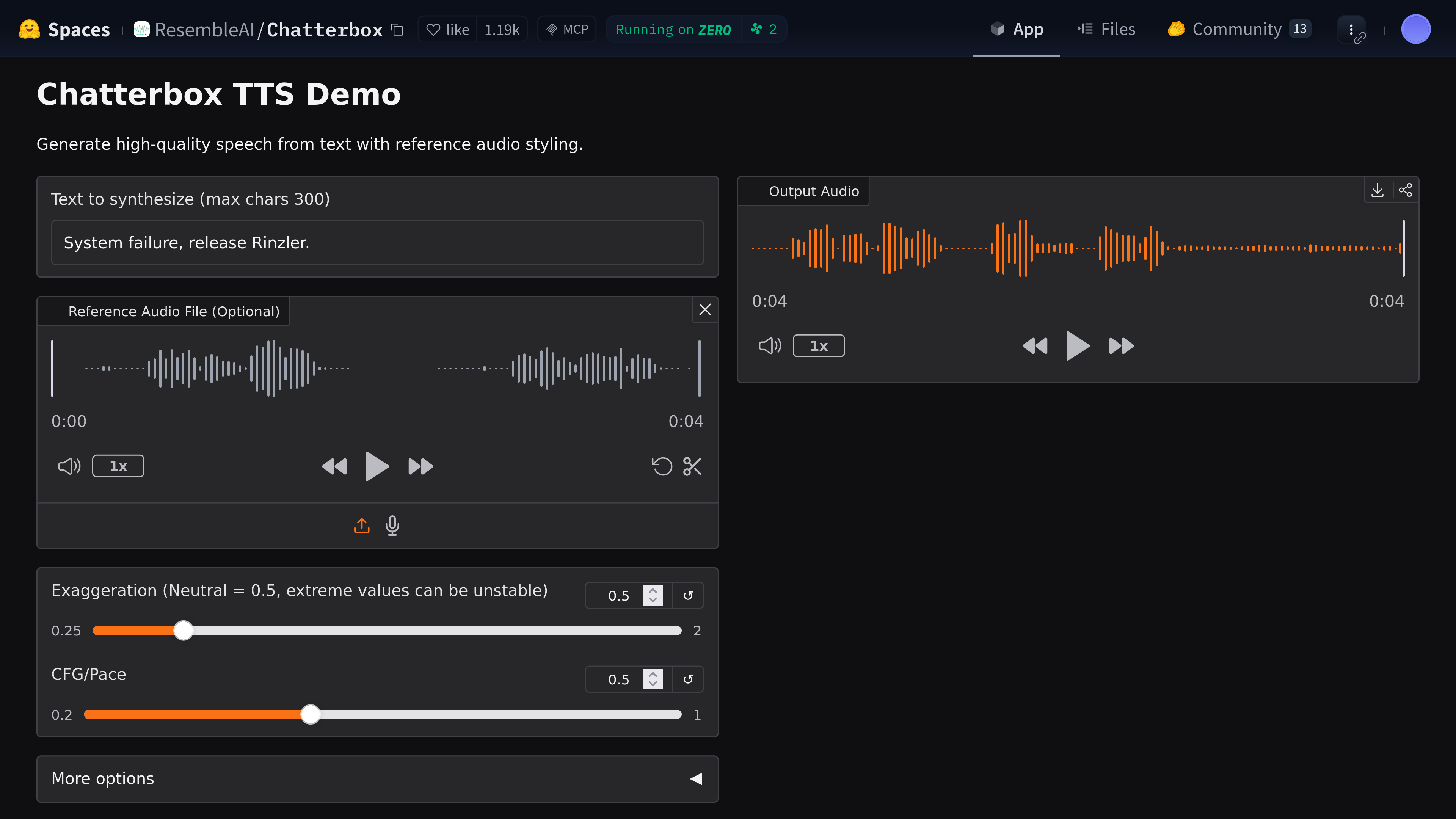
Heavyweight AI TTS: Chatterbox
Chatterbox TTS is a particular achievement in that it is “zero shot.” This means it can clone a voice using a single phrase – without any additional training! There is a demo available on Hugging Face which allows you to try it out.
The state of the art models are in varying states. They may require expensive hardware to be as performant as Piper, or otherwise are in a fairly experimental state. As such I wanted to use Piper.
Training a Piper voice traditionally
Piper has some documentation on how to train a new voice. Plus, there are lots of youtube tutorials available.
Generally training involves collecting a dataset of audio samples together with the corresponding text, and feeding them into the training scripts which require a recent GPU.
If you have a large dataset, you can train from scratch. However, it is possible to “fine-tune” an existing model with a smaller dataset – in this context it means grabbing a checkpoint from an existing model and training it further with your own data.
Typically, around 2000 epochs are required to train a new voice from scratch, while fine-tuning requires an additional 1000 epochs. Presumably, epochs will take longer with a larger dataset.
About 1300 phrases seem to be recommended for fine-tuning, and 13,000 for training from scratch.4
There are tools available to help you collect the dataset, such as piper-recording-studio.
Based on looking into the training done here: https://brycebeattie.com/files/tts/ ↩︎
The idea
As you’ve likely guessed, I wanted to use Chatterbox TTS to generate a dataset from a single phrase, and then use that to fine-tune Piper TTS. Given the layers of transformation, I didn’t expect the result to be an exact copy.
So I picked a sample phrase generated by the legacy TTS engine.


That same phrase regenerated with Chatterbox TTS:

They sound similar! Chatterbox has made the voice sound less robotic. This is OK, but it does make it sound slightly less sinister…5
Next I had to write scripts to generate a dataset from this. That meant running Chatterbox TTS locally.6
Hardware
While my main desktop PC is a powerful machine, it has a rather ancient GPU: a Nvidia GTX 980Ti7 which has only 6GB of VRAM and the Maxwell architecture which is no longer supported my most PyTorch projects.

As it happens, I ended up with a friend’s Tesla P4 GPU that we had previously used for transcoding. It has a Pascal architecture and 8GB of VRAM, which is marginally good enough.8 Apparently it is approximately equivalent to an under-clocked 1080ti. I bet newer cards would be far faster though as they have been designed with AI explicitly in mind.

Given this card is a (circa 2016) datacenter GPU, it has no video output so I could not put it in my main desktop which has only one PCIe slot and no integrated graphics. I have a lot of spare hardware lying around so I threw together a case-less system.9
The system has an ancient first generation i7 and only 8GB of RAM, but given the training happens entirely on the GPU, this shouldn’t be a problem.
We were going through a heat wave in the UK, so I set up the system outside under my pergola to keep it cool. …I’m hoping there won’t be any stormy weather before training is done!
Software
NixOS and Docker
I used NixOS as a base, given I can set up a new environment in minutes on a new machine.10 Docker was used together with a wrapper script to make executing the various scripts I developed for each stage easier – I suppose I could have used a nix-shell, but something told me I didn’t want to effectively package and port the whole thing to Nix given the training scripts are experimental and likely to change.
“I run NixOS, BTW.” I had to mention it somewhere, right? ↩︎
Dependency hell
Suffice to say, given the experimental nature of the Piper TTS training scripts, I hit a good chunk of dependency hell. This is understandable given training is a one-shot thing – the training scripts are not packaged or maintained quite to the same level as the main project.
Anyway, if you want to play along I’m including all the scripts I wrote in this post. Beware; while they worked for me when I wrote the post they probably won’t later – the code is littered with unpinned dependencies and deprecation warnings.
The process
I used TRAINING.md as a guide, so I recommend you read it too first as is covers some things that I don’t.
Dockerfile and wrapper script
Assuming you have Docker and GPU drivers installed, I’ll start with the Dockerfile, which includes a few hacks to pin dependencies where APIs have otherwise changed. I based it on the recommendation in the training guide.
| |
The Dockerfile above sets up the environment with all the required dependencies for all the tools used here.
Crucially it sets up some caching configuration so you don’t have to hammer the Hugging Face servers to download weights every time.11 To actually run the scripts, I created a handy wrapper – a mainstay in many of my docker-powered projects.
| |
The wrapper script above allows you to execute scripts in the current directory, but in the environment from the Dockerfile. File ownership is even preserved.
To use it, run ./docker-wrapper.sh <script>. All of the scripts included in this page assume you run them this way.
Note the GPU passthrough – in NixOS I had to set hardware.nvidia-container-toolkit.enable = true; for this to work.
Only when combined with the wrapper script. ↩︎
Corpus text gathering
I combined the corpus from the aforementioned piper-recording-studio with the phrases from the EdgeTX firmware and some quotes I’ve kept over the years. This gave me a corpus of about 1300 phrases and a reasonable coverage of the English language sounds.

The (trivial) script is available above. I included it as it might save a few minutes parsing things manually if adapted.
Generating training data
Here’s the tricky part; in theory all I had to do was run the Chatterbox TTS engine over the corpus text, and save the each generated audio sample to a file.
Using my Ryzen 5950X resulted in a generation speed of about 8 seconds per phrase which was fast enough – I did most of the generation on my desktop before setting up the training system.
Nonsensical audio samples
However, while this seemed to work OK I quickly realised some of the produced files were nonsensical or corrupted. Given the stochastic nature of AI, and the fact that Chatterbox is brand new, this is not surprising.
For instance, here’s Chatterbox TTS trying to say “zero”:

…to me that sounds like “Win, beach and Prius.” Madness! For some reason zero trips it up nearly every time. Certain other numbers to too! I speculate this could be due to a small input phrase length triggering a bug, or simply bad training data.
Why is this a problem?
If this corruption made it to my training set, it could throw off the resulting model entirely. I had to find a way to automatically fix this problem without manually inspecting every file.
Fortunately, re-attempting the generation of a phrase with Chatterbox TTS can sometimes result in the correct output – as the engine is stochastic, it is non-deterministic unlike traditional TTS engines such as Festival or espeak.
Verifying without listening, with Whisper
Luckily for me, in addition to the advancements in Text-to-Speech, there have been parallel leaps in transcription engines too. Whisper, from the ironically named OpenAI,12 is now the gold standard.
Like Piper, it’s also lightweight enough to run on a low-power system and fast.
The plan was to use Whisper to transcribe the generated audio samples, and then compare the transcription to the original text. If they match, the sample is good! If not, my script retries a few more times.
Ok, in this case they live up to their namesake (and published papers) ↩︎
But…
A problem with this approach is that there are often several valid ways of transcribing a given phrase:
- Americanisms: “color” vs “colour”
- Punctuation: “Hello world!” vs “Hello world”
- Numbers: “zero” vs “0” – phonetic vs numeric
- Combined words: “wheelbase” vs “wheel base”
- Probably other things.
At first I used regexes to replace non-word characters with spaces. I realised I’d need something better if I wanted more than the resulting 88% coverage though.
I considered using some kind of fuzzy matching with the Levenshtein distance or a lexicon to make up for the problems in this particular corpus, but that felt like a bad solution.
Phonemes to the rescue
Revisiting, I thought about what my kids had been learning at school – phonetics! Word sounds are broken down into phonemes, which are not sensitive to spelling variations, punctuation or Americanisms. If I could covert the original text, I could compare the phonemes instead and bypass the issues above.
Earlier I had noticed that Piper TTS has a dependency on espeak-ng. Curiosity had got the better of me and I had looked into it. It turns out espeak-ng is used to outsource the phoneme conversion. Luckily, this is exposed in the Piper python library.
Here’s a quick demonstration of its effectiveness:

What you can see is a collection of unicode characters representing the International Phonetic Alphabet.
Employing this method, coverage rose to 98% (1644/1677) – I was happy with that! Here’s the script:
| |
You may have noticed that the script above writes the data in a specific format, “LJSpeech” compatible. This is a common format for TTS datasets, and the Piper TTS training scripts support it.
LJSpeech is a public domain dataset of English with about 13,000 phrases. It has a simple CSV file with wav files indexed by a numeric ID. It is established as the de-facto standard for TTS training sets.
Converting the dataset for training
Piper TTS training scripts expect the dataset to be in a specific format – 22050Hz mono. Chatterbox produces the files at 24000Hz so I needed to first convert the sample rate, else I suppose the model would learn from files effectively slowed down.
After this, the LJSpeech-compatible dataset needs to e converted to another format, as it is probably due to PyTorch. There are scripts to do this in the Piper repository. 3-gen-training-data.sh does this:
| |
Training, from the LJSpeech checkpoint
Now for the main bit! There was a lot of wiring and converting to get to this point but the rest is easy provided the GPU is set up correctly.
Here’s the script, which just runs the Piper training script included with the piper source:
| |
Versus the example in the Piper documentation:
- I set
--batch-sizeto 12 (empirically) as the Tesla P4 has 8GB of VRAM and the example batch size is 32, which apparently requires 24GB of VRAM. I did a bit of searching about the implications here, and only speed and the measurement of progress seems at stake instead of the quality of the resulting model. Note that the maximum phonemic length for every file is a factor here. - I used the LJSpeech piper checkpoint in high quality from here. I had to tell it
--quality hightoo. - I set
--epochsto 3000, as I was fine-tuning an existing model already at 2000, wanting to add 1000 as explained earlier.
TensorBoard
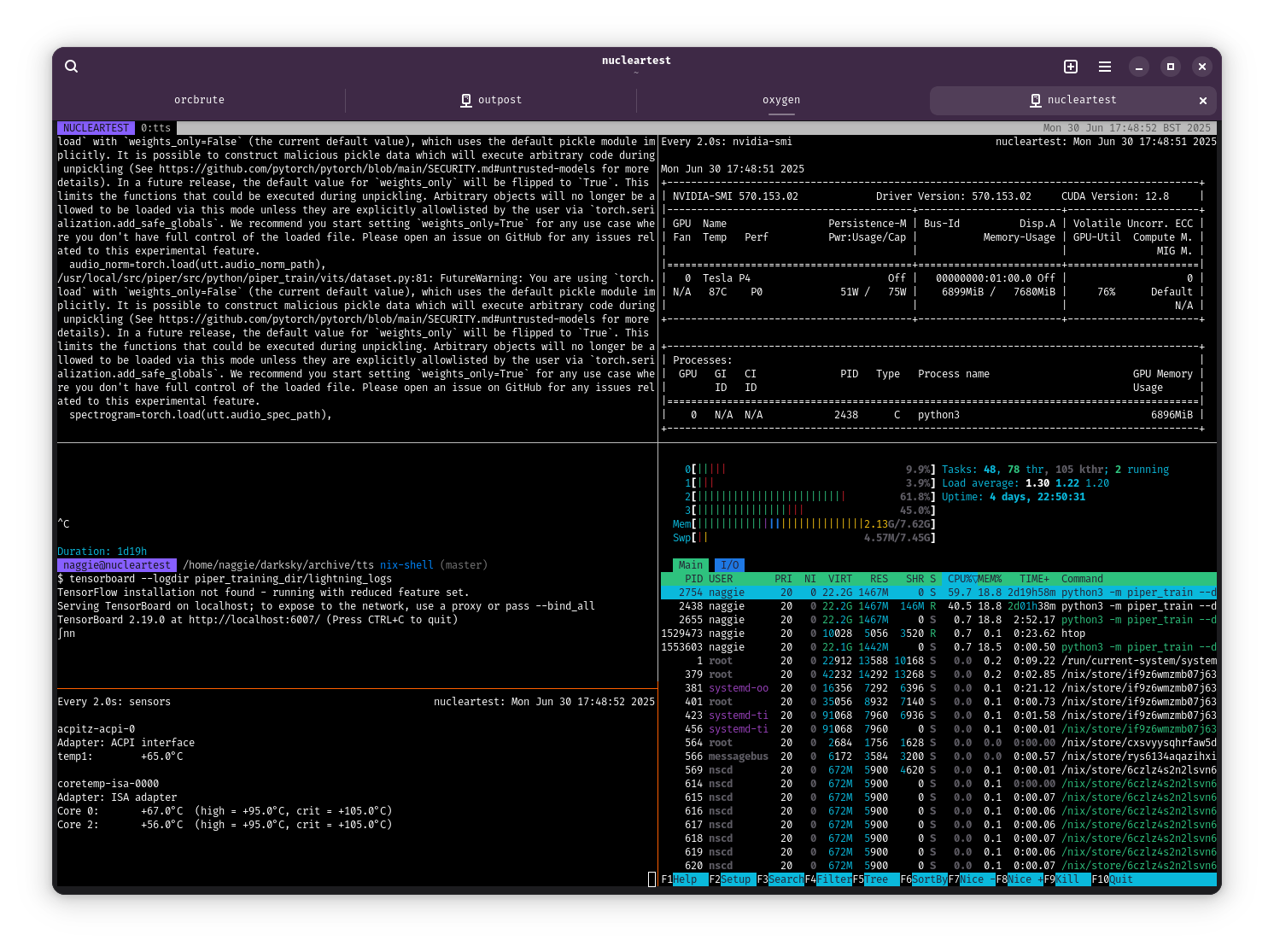
It’s possible to observe the training progress in real time using TensorBoard – a tool that generates graphs based on the logs stored within the training directory.
For speed, I just used nix-shell: nix-shell -p python3Packages.tensorboard --run "tensorboard --logdir ./piper_training_dir". I then made an ssh tunnel to open http://localhost:6006 in my browser. Here’s what it looked like from the first few minutes:
The aim is to see convergence of the loss function, in this case known as loss_disc_all. I presume disc stands for discriminator, and is what the loss function is called.
The training process will save the weights every so often, in structures known as checkpoints. In theory this happens every 1 epoch as configured above, but empirically I discovered that it happens every 100 epochs. Perhaps that’s the minimum interval.
Exporting the model
Assuming training was successful, the final step is to export the model the standard format: Weights in and onnx file + some metadata in a JSON file.
The resulting model can be simplified with the onnxsim tool.
| |
Results
When running the data generation script, it was interesting to see the mistakes caught. They range from bizarre to amusing, and some are just plain misleading. Here are a few examples:
... LJSpeech-1.1/wavs/4.wav: expected '4', got ' he now is recording'
... LJSpeech-1.1/wavs/187.wav: expected 'timer 2 elapsed', got ' Timmer 2 elapsed.'
... LJSpeech-1.1/wavs/187.wav: expected 'timer 2 elapsed', got ' Timmer 2 elapsed.'
... LJSpeech-1.1/wavs/6.wav: expected '6', got '26'
... LJSpeech-1.1/wavs/471.wav: expected 'Dig mode', got 'Dick mode.'
As mentioned above, I ended up with a dataset 1644 phrases.
Starting the training resulted in a mountain of deprecation warnings. Things change fast in the AI world! See the terminal screenshot to see what I mean.
Training was interrupted on purpose to relocate the system outside (under cover!) due to heat. I expected the system to resume seamlessly, but unfortunately I had loss quite a number of epochs as the checkpoint was older than expected.
This can be seen in the loss function graph – grey is version 10, with the blue (version 11) starting before version 10 ended.
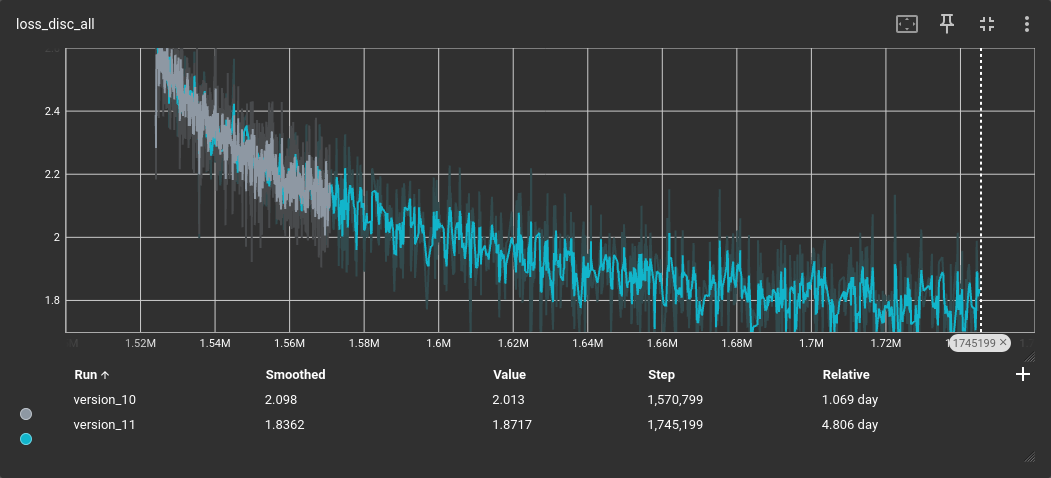
Over 1000 epochs, the graph shows convergence! The noise is quite high though, probably due to the low batch size.
The process took around 5 days. Exporting was successful, though simplifying the model only took about 0.2 MB from the 100MB model.
Here’s the test phrase generated by the new model!

It works! It sounds similar to what Chatterbox TTS generated. At that point I realised I should have used a better example phrase throughout this post. Here’s a longer clip of the same voice, generated by the new model:
A rainbow is a meteorological phenomenon that is caused by reflection, refraction and dispersion of light in water droplets resulting in a spectrum of light appearing in the sky.
This is from the Piper project, used as a test phrase.

Given the unknown copyright status of the generated weights, I will not release them. The process here was used to generate a custom voice based on an example from a commercial TTS engine, but it could apply to any other source of speech.
Conclusion
I successfully fine-tuned a Piper TTS voice based on a single phrase. The process was quite tedious due to the level of moving parts dependency issues, waiting for processing and the manual steps; however it was definitely worth it and I hope this article makes it easier for anyone else to do the same.
I think the main application for this is to create a custom voice for home-assistant.
What’s next?
Clip silence from training data
In the generated chatterbox sample from earlier there is a significant period of low level noise at the end. You can see this on the spectrogram. I wonder how much of the training set has this problem, and how much it affects the model. I will use sox to clip this from the training set and try again to see what difference it makes.
Perhaps it’s something to do with the audio watermarking employed by Chatterbox TTS?
Train from scratch
It would be trivial to use the same procedure to produce a much larger training set, perhaps based on the LJSpeech corpus text. This would give me the best possible representation – though depending on the quality of Chatterbox versus the checkpoint I used for this article, it might not sound better!
I suspect I’d also need some much beefier hardware and much more time. That can be arranged.
Given I think I’d need about 13,000 phrases to train from scratch, it could take 200x longer to train assuming a linear relationship between the number of phrases and the training time, with 2000 epochs.
This could take years on my current hardware at that rate, so I’d probably have get access to something more powerful. Because of this, I think the fine-tuning approach is the right compromise.
Voices from films or games?



How about making some Piper TTS voices based on some evil AIs from various films or games? What would be fun.
Cal Bryant

Thanks for reading! If you enjoyed this article or have comments, please consider sharing it on Hacker news, Twitter, Hackaday, Lobste.rs, Reddit and/or LinkedIn.
You can email me with any corrections or feedback.
Tags:
Related:

