
Moving on after 12 great years at Cydar
The cover image above is of the first Cydar HQ, a converted water mill in Cambridgeshire. It was a glorious setting for a startup, and was a nice change from the corporate offices of Broadcom.1 I was known to swim in the mill pond on hot days, and once had to chase a loose sheep! We even made some Cydar Cider2 from the orchard on site in my first few weeks.
I was working late one day at Broadcom, and spoke with John, who was leaving to become the CTO at Cydar. I asked him where he was going. A few chats later, I was interested in the engineering position available; I wasn’t sure I could do it but sounded it like an opportunity I couldn’t turn down.

I had an interview and was later offered the job – to implement the cloud compute platform to make the proof of concept into a cloud powered product.
I joined Cydar in July 2014 as a Senior Engineer and progressed through to Principal Engineer, Head of Engineering, and finally VP of Engineering. I’ve been fortunate to grow multiple teams, and I’ve also been heavily involved with operational improvement and company vision.
I’m grateful for the opportunities I’ve had to grow personally and professionally, and to work with such a talented, fun and dedicated team with great mentors3 along the way.

Fast-forward 12-years and I’ve decided to move on – it’s been a challenging, fun and monumental journey; I’m extremely proud of what we have achieved at Cydar in this time. I’ve seen and helped the company grow from a small startup to what it is today, supporting thousands of surgeries around the world.
I made the tough decision to leave and pursue a new opportunity at Hypervision Surgical4 in London5 to build their cloud platform.6 I wanted a new challenge, and to prove to myself I can do it all again.



So what did I do at Cydar?
I couldn’t leave without writing about Cydar, so I’ll cover some of my favourite projects and milestones in this blog post, and reflect on what I’ve learned along the way.
I did like the more modern, corporate offices! Great labs and I got to know most of the 150 people there. ↩︎
Named “False positive” ↩︎
Thanks Paul, Graeme, Tom, Vanisha, Rob, Prasanna ↩︎
Hypervision surgical builds AI powered hyperspectral imaging systems that give surgeons real-time, non-contact tissue characterisation to make surgery more precise, safer and faster. ↩︎
The office is opposite the houses of parliament. Talk about a change of scenery! ↩︎
12 years is a long time! I’ve moved house, got married, had 2 kids and seen the world change beyond recognition in that time. ↩︎
Overlays, delivered in a few seconds!
My first remit, alongside Rob Hague was to build upon the prototype implementation of an early version of Cydar maps to make it into a cloud-powered product that was 10x faster and able to provide service to multiple users at once.
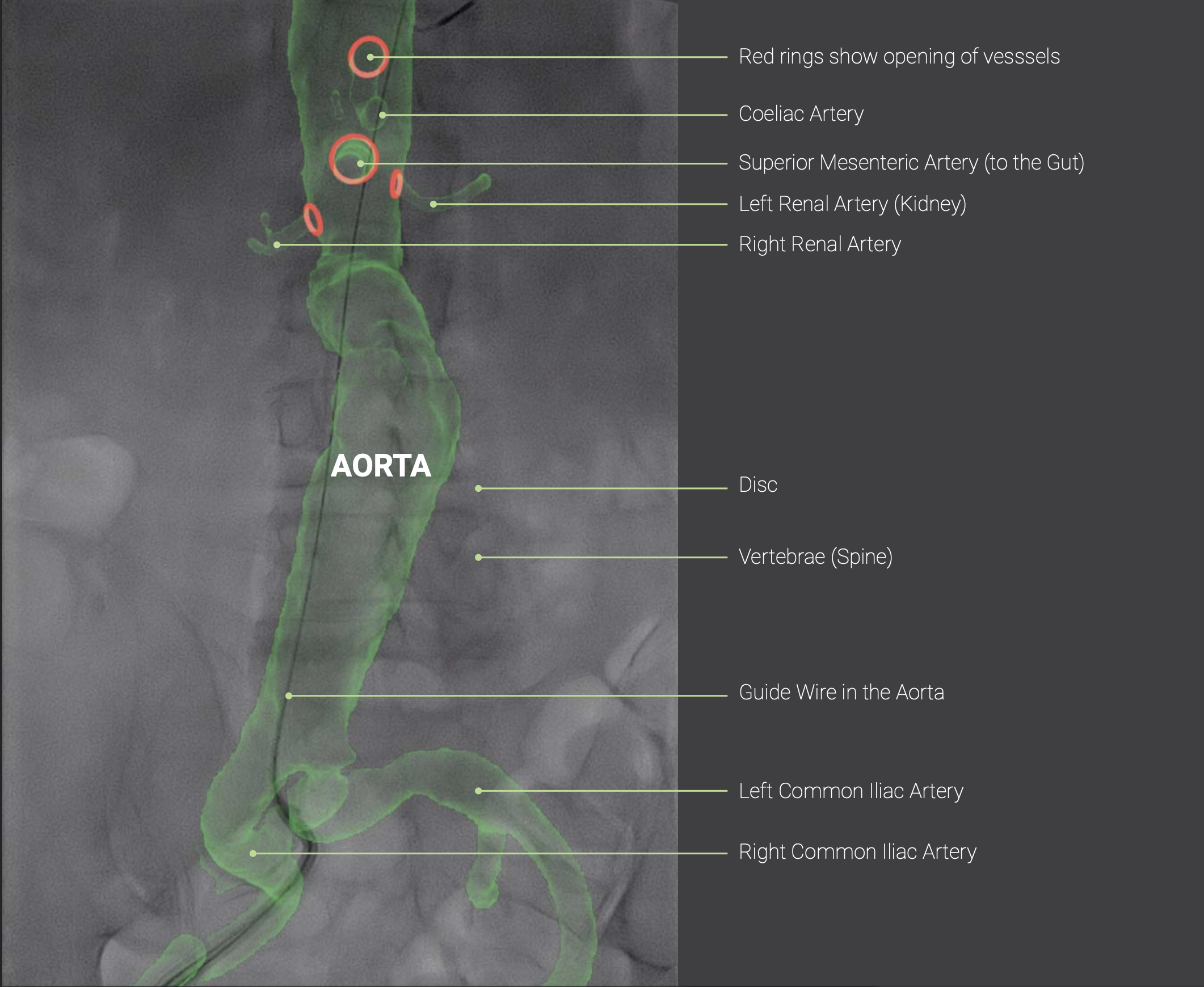
The system, much like today, looks at the live fluoroscopy video feed from the operating theatre and attempts a 2D-3D registration between this image and the pre-operative CT scan of the patient. If successful, the 3D cut-out of the aorta from the CT scan (angiogram) is then overlaid with reverse perspective.
The prototype was based on something called “the beast”7 which was an extremely beefy gaming PC. It had 4 GPUs and was powered by CUDA. We literally wheeled it into the operating theatre at St. Thomas’ hospital in London8
When I joined, Rob had already separated the implementation into a web-based client/server. The client was, naturally, called “beauty.” We deliberately threw this one away.
At the time, the system was deemed surgically useful but it took an agonising 50 seconds9 to resolve the position of the overlay. My remit alongside Rob and Andreas was to move the compute (necessarily!)10 to the cloud and parallelise the registration to make it resolve in 5 seconds or less. I remember thinking it wasn’t possible, but I never told my John that. Anyway, we kept plugging away at it and eventually got it down.
I implemented a work-queue system using Redis to co-ordinate the work across multiple GPU servers. This is where I also focussed on availability – we used 56 compute workers so the system was by default 56x likely to fail if we depended on getting an answer from all of them. Given there was some spacial redundancy in the system, and for any given registration only a few workers actually contributed to the result, I implemented a system to time-out the last few results if some workers got stuck.11
To pass data around I implemented a low-latency content addressable storage storage system on top of S3. This is still in use by Cydar today as it has some sizeable advantages:
- Tamper-evident – the chain of trust doesn’t depend on the storage location so long as the hash is stored in a trusted location
- Intrinsic integrity checking – if the data is corrupted, the hash won’t match
- Intrinsic de-duplication – if you store the same asset twice, it will be stored once

When combined with Merkle trees the real power is apparent – the ability to verify the integrity of a large dataset combined from a complex system with a single hash. This is how I was able to guarantee the association of the overlay and data with the correct patient within the operating theatre, robust to confusion of data caused by a class of bugs or operator error.12
The CAS references also made it easier to separate the patient identifiable data from the imaging data. Essential for a compliant system that respects patients’ identities.
Because of this necessity of moving to the cloud for the compute power, nowadays Cydar’s product is a lot stronger than it would otherwise been. It’s thanks to this connection to the cloud that the product has been able to be developed to what it is today, with a lot more AI powered, fully remote and collaborative features.13
I wish I had a photo of the beast! ↩︎
St. Thomas’ hospital is literally next door to the Hypervision offices. What a small world! ↩︎
It used to take 15 minutes on Graeme’s (CSO, co-founder) laptop. Now that took real patience! Andreas, Cydar’s research fellow was responsible for reducing that time to 50 seconds with the (nascent) CUDA ↩︎
There was no way we could have done this cost effectively with local hardware. ↩︎
It’s actually possible to make the system “too reliable” if you can’t detect failures. We once had a problem where a few workers were systematically stuck (bad hardware) but we couldn’t tell as the system worked fine. ↩︎
This, and an effective QA team (and CI) was a big part of reason I could sleep at night. Sometimes it hit home that people’s lives could depend on the software we wrote. ↩︎
I think we were accidentally ahead of the curve in this case. With the right data architecture, it’s now the norm to be cloud connected. ↩︎
Making deployment to the theatre reliable and inexpensive
Like the your IT department: when everything works “why are we paying you?” and when things go wrong, “why are we paying you?”
If the system is working well, nobody notices it. That’s how it should be.
Cydar’s software runs in the cloud, accessed via a web browser; but it also has an inevitable presence inside hospitals – in data-centres and also in operating theatres on a physical computer connected to a fluoroscopy machine.
These machines in the operating theatre need to be reliable, secure, and performant. They are also deployed in an environment that may be hostile to software – unexpected loss of power,14 network outages and a limited15 ability to intervene in person when there are problems.
Our client device in the operating theatre is based around a standard web browser, among other applications. These applications require periodic updates and can sometimes crash; in fact we hit a tough and deeply embedded Chrome bug to do with its javascript garbage collector at one point early on.
I developed a system to manage these machines remotely, as appliances, without replying on traditional remote-desktop style software. This system, known internally as “agent” has been in production for around 6 years now, with nearly 200 installs.
Given Agent is another moving part, a lot of work was put into making it improve the reliability of the system as a whole instead of making it worst. For instance, there is a fail-safe mechanism built in should the control server be offline. There is also a recovery mechanism should any component crash.
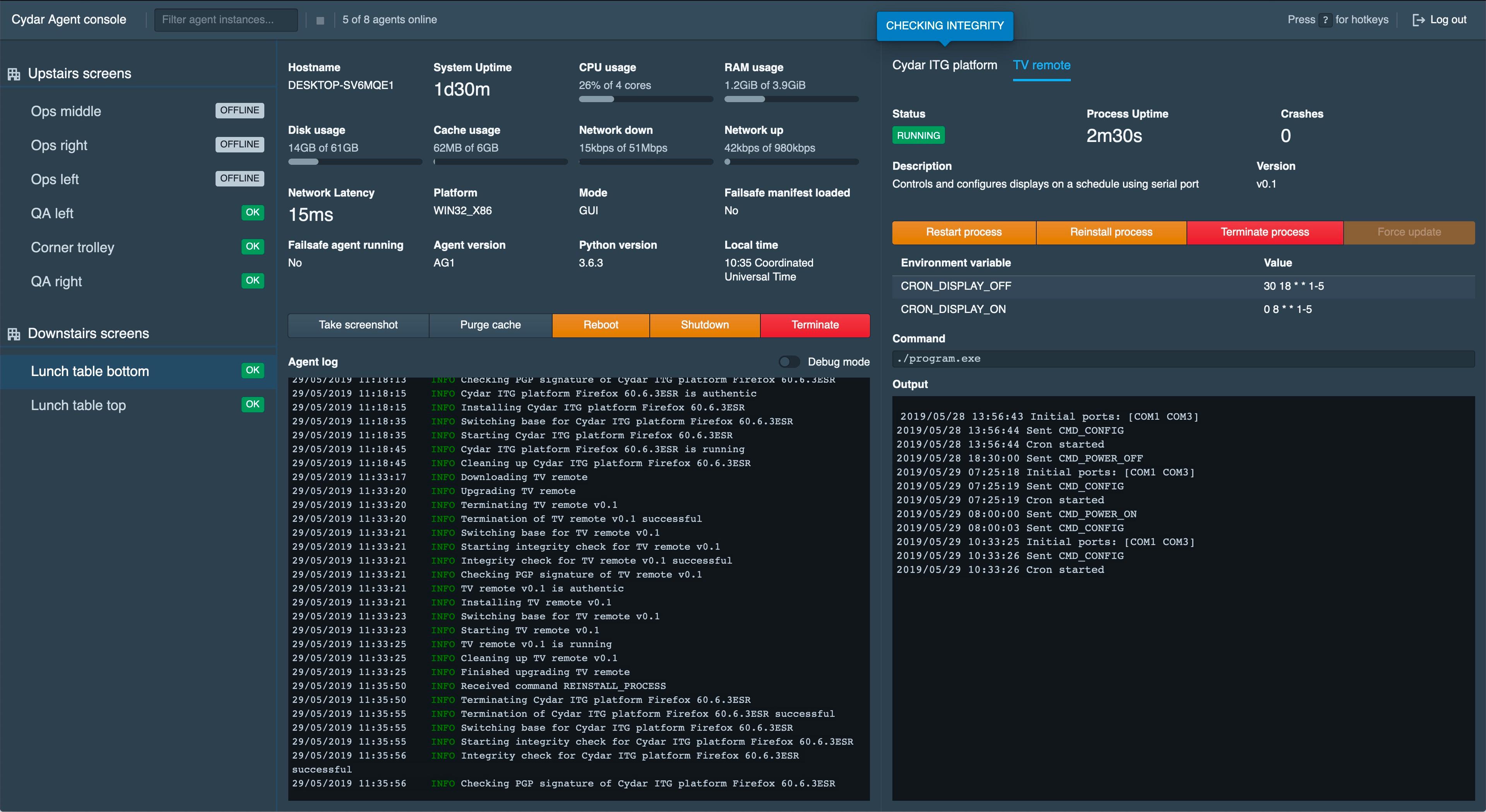
Agent uses GPG to establish a chain of trust to allow only software signed by Cydar to run, including itself. It uses the content addressable store mentioned earlier as a further integrity guarantee.
Agent uses GRPC to establish a strongly typed protocol between the clients, server and Cydar’s central software management system. This allows for easy implementation changes without the risk of incompatibilities.
Interestingly, when developing the system in 2018, I discovered a bug with the new grpc_pass feature of nginx. I set up a few scripts to isolate and reproduce the bug, and amazingly the nginx team fixed the issue and released a new nginx version in just 4 hours!
Agent is mostly deployed on top of Windows. Windows has been an ever increasing battle – despite using the IoT Enterprise LTSC edition, Windows became more and more hostile making it difficult to manage – forced updates, stability issues etc.
In 2025 Agent was extended to become AgentOS to eliminate windows. I worked on this with Leo, a principle engineer on my team. The solution allowed for some incredible improvements:
- The biggest one: The whole OS and state is ephemeral by default. The OS runs in a RAM disk, so only explicitly chosen changes are persisted to disk. This means we’re starting from scratch on every boot so the entire system is deterministic
- The entire OS was around 100MB – tiny compared to a windows install (20GB or something). Idle RAM/CPU usage was also minimal.
- As such, the OS itself could be updated like an y application
- An A/B updater with a blessing system like ChromeOS des – this requires a new OS image to prove it is functional before switching fully
- The initial install takes seconds, and is straightforward
The result is a system that is really difficult to break, easy to update and secure by default. It is used by Cydar to run our in-theatre software package, as well as our PACS gateway.
Solving interaction in the OR with a custom remote
At inception, Cydar maps required exactly one interaction in theatre: to confirm the identity of the patient before surgery. The rest was automatic! This was a big selling point, in my opinion, as “the best interface is no interface.”
However, in late 2018 we introduced a new feature – the deformation adjustment tool (DAT), alongside some later features: streaming the screen elsewhere as well as screenshots.
Cydar can still operate with this one interaction, but with the DAT it is possible to update the anatomy to reflect what has happened during intervention as the deployment devices can change the shape and position of the Aorta.
As such, we introduced touch-screen controls. This worked OK in some operating theatres that could afford the space for the extra trolley, but wasn’t a practical option for hybrid ORs that had gantry mounted screens (with a video distribution system, allowing Cydar to be cast to the screen) without a touchscreen.
Touching the screen was also impractical in some cases, and was often done by proxy of someone else due to proximity.
Cydar needed something else, and it needed to work with touchscreens as well.

The first thing I did was look for existing devices to prototype with. Cydar had previously used a Kinect, but that didn’t work out. Voice control would have been awkward; it’s bad enough trying to get Alexa to turn on the lights…16
Some companies use an Xbox controller in operating theatres17. It makes sense, as they’re robust, highly available and already familiar to a lot of people.
An amazon/apple TV style remote was also an option as it allows for simple one-handed control without looking at the controller. I ended up going for that as a form factor, as the interaction we required didn’t need as many buttons as a game controller, and 2 handed operation was cumbersome.

Look at the traditional TV remove vs the modern apple TV remote. There were several key differences that where important to Cydar’s use case:
- The Apple remote has few buttons, in clear places. Meaning you can use it in the dark, and without looking at it. No awkwardly angling it at the TV to figure out which of the 57 buttons to press.
- The Apple remote has tactile, clicky buttons! They don’t squish down, so when you click you know you’ve definitely clicked. Clicking is also faster.
- The apple remote relies on the UI to present menu based control for everything.
Given the need for touchscreens and a remote, the interface either had to support both or we needed 2 interfaces. The latter would have increased training costs and a barrier to entry, so the solution was a hybrid where the remote ordinal controls select a button that could otherwise be touched on the screen.
To do this I wrote an algorithm to rank the buttons for a particular direction, and select the closest one with a vibrant colour. This worked well with the existing interface; we also chose to optimise some parts of the UI if the remote was detected – for instance, soft-key shortcuts as I planned to have some A/B/X/Y general buttons.
We tested this algorithm in-theatre using a bluetooth media remote, and soon noticed that it was sometimes unclear what button was targeted if the target was the other side of the screen. The solution was an animated green ball! That made it obvious with a visible green trail.
Quickly, the bluetooth remote literally fell apart and soon had pairing and battery issues, as well as range problems. Terrible! The real solution was going to have to be far better.

I prototyped a solution, settling on an Atmel microcontroller and LoRa modem. Across regulatory regions, this choice together with thoughtful power design (deep sleep modes, no regulators) allows for:
- Super long range. I ran down the end of the mill road and was still able to control a machine reliably
- Extended battery life. I didn’t want users to have to charge the remote (it wouldn’t happen reliably) so by using alkaline batteries I was able to predict a standby battery life of a decade or so. Later on I even implemented global monitoring of battery state so we can preemptively replace batteries if there’s an issue.
- Good signal penetration. At around 900MHz penetration is less of an issue compared to the (also crowded) 2.4GHz of bluetooth. In some installations, the final remote receiver was able to be placed 5 rooms away without issue! This required a lot of experimentation with modem parameters and a custom protocol to avoid latency issues.

To design and manufacture this project I outsourced the electronics design firm together with a mechanical engineer, graphic printing, PCB manufacturing and EMC testing company. I contributed on the electronic design and fully implemented the software from the embedded code to the cloud.

I chose an existing generic enclosure and worked with a keypad manufacturing firm to produce a tactile membrane based keypad insert to go with it. I was able to prototype button positions and height with my 3D printer.

After a few delays due to a certain pandemic – manufacturing and part availability – we deployed the remote worldwide.
Interestingly, the ops department noted the touchscreen usage went down to basically zero! We never had a single issue18 in the 4 years we’ve had the remote deployed. Success!
“Several devices share that name” – arrgh. ↩︎
They’re also good enough for the navy on submarines, apparently! ↩︎
Well, unless you count remotes ending up lost or in the autoclave… An invoice later and some were magically found ;-) ↩︎
Implementing SAML2 single-sign-on to win our first US customer
In late 2017 we won our first US customer after our 510k FDA clearance. This was a major milestone for the company. I remember it was touch-and-go getting the agreement signed; the agreement ended up hinging on the implementation of SAML2 single-sign-on to integrate with their Shibboleth identity management system.
I ended up writing a custom SAML2 service provider directly integrating into our Django19 powered patient database.
SAML2 can be rather complicated, and as such there are a lot of opportunities for security issues to creep in – it is susceptible to quite a lot of attacks by design. The 2 most significant that I had to mitigate:
- The use of in-band signatures. This is a bad part of the SAML2 spec where differences in XML parsing behaviour can be exploited. Really the only defense against this is to keep
libxmlsecup to date. - Cipher downgrade attacks. Much like SSL and JWTs there’s a protocol to negotiate the “best” the client and server can mutually speak. If weak ciphers are available, they could be forced by an attacker in some situations as the requests are marshalled via the browser.
Cydar’s SAML2 implementation is now connected to the majority of our hospitals and reduces the administration effort required from both hospital IT and Cydar Ops.
One of the better choices. The documentation, stability and maintenance of the project exemplary. I remember our CTO telling me to “choose boring” (stable) which was not necessarily what 23-year-old me would go for – 2014 development was… somewhat hype driven ↩︎
My favourite bug
It’s the typical interview question – what was your favourite bug?
Mine was performance issue with my PACS gateway; it was transferring scans about 15x slower than it theoretically should have been on a windows VM.
Looking into the problem with profiler, the library I was using was spending most of its time sleeping! As it turns out, it has an event loop which sleeps for 1ms to (presumably) prevent hammering the CPU.
As it turns out, Windows has more than one scheduling mode – by default, the timer granularity is 15ms. As such, that 1ms became 15ms – resulting in 15x slower DICOM scan transfers!
It is possible to request a 1ms timer mode from windows instead. This mode optimises for latency over throughput and presumably battery life. Anything that plays a video needs this!
Given the time it takes to spin a gateway release, and the need to validate the hypothesis, I asked the ops team to play a YouTube video on the VM when making a transfer to see if it makes it any faster.
To the astonishment of the Ops team and Hospital IT, it did!
A small change to the gateway to request the new scheduler mode later, and all sites with a windows VM were able to benefit from this improvement.20
A satisfying, yet annoying improvement because we could have found it earlier. ↩︎
Conclusion
I was part of delivering what was probably the first cloud connected operating theatre21 and got to be part of a tiny startup that turned into something much bigger with an international footprint and had a great time doing it.
Here’s to the next years at Hypervision! Thanks, Cydar.
Feel free to dispute this. I’m not sure! ↩︎
Thanks for reading! If you enjoyed this article or have comments, please consider sharing it on Hacker news, Twitter, Hackaday, Lobste.rs, Reddit and/or LinkedIn.
You can email me with any corrections or feedback.
Tags:
Related:

